研究背景
類風(fēng)濕性關(guān)節(jié)炎(RA) 的診斷主要基于臨床癥狀和類風(fēng)濕因子(RF),抗瓜氨酸肽抗體(抗 CCP) 的血清學(xué)陽性,而銀屑病關(guān)節(jié)炎(PsA) 只有臨床和影像學(xué)特征有助于診斷。雖然大多數(shù) RA 患者 RF,抗 CCP 血清陽性,但約 15%-20% 的 RA 病例中,血清中 RF 和抗 CCP 水平并未升高,由于血清陰性 RA(negRA) 和 PsA 的癥狀非常相似,且沒有可靠的臨床標志物,因此 , 兩者的鑒別診斷十分困難。由于治療方法不同,可靠的診斷對于開出正確的治療處方很重要。此外,導(dǎo)致 RA 和 PsA 患者特征性關(guān)節(jié)破壞的慢性炎癥過程可能會引起細胞、組織和器官代謝的重大和不同程度的改變。這些代謝改變導(dǎo)致血清代謝物和脂質(zhì)體的改變。因此研究者對 negRA 和 PsA 患者血清進行了基于 1H NMR 的代謝組學(xué)和脂質(zhì)組學(xué)分析,識別 negRA 和 PsA 患者血清中濃度不同的代謝物和脂類。從這些數(shù)據(jù)中推導(dǎo)出一個模型,將患者分類為兩種疾病類別中的一種,隨后進行了盲法驗證隊列分析,確定生物標志物來提高這些疾病的鑒別診斷。
實驗方法
檢測方法:靶向代謝組學(xué),脂質(zhì)組學(xué)
檢測平臺:NMR
樣本分組:negRA 患者 =49 例;PsA 患者 =73 例
研究結(jié)果
核磁共振波譜分析
使用 TopSpin 3.6.2 軟件(Bruker BioSpin GmbH) 處理 NMR 譜。使用 AMix 軟件整合單個已鑒定代謝物的相關(guān)光譜區(qū)域以進行定量。代謝物濃度的 jué對定量是通過比較來自每個代謝物的信號積分與富馬酸內(nèi)標的信號積分來實現(xiàn)的。
在 1H 單脈沖 NMR 譜中,同時觀察到來自小分子和大分子的峰,導(dǎo)致基線不均勻和來自不同化合物的信號重疊。盡管如此,由于其特有的光譜特征,可使用 1HNMR 來識別和定量血清中的脂質(zhì)。如圖 1A 所示,圖中有七組脂質(zhì)信號(L1-L7):L1:脂質(zhì)甲基;L2:脂質(zhì)脂肪鏈;L3:脂質(zhì) β - 亞甲基;L4:脂質(zhì)烯丙基亞甲基;L5:脂質(zhì) α - 亞甲基;L6:脂質(zhì)多不飽和烯丙基亞甲基;L7:脂質(zhì)烯烴。
在 CPMG NMR 譜中,通過抑制來自脂質(zhì)和蛋白質(zhì)的寬信號,所得的低分子化合物的峰不會被來自大分子的信號所掩蓋,且具有清晰的信號和明確的基線,因此可以更好地識別和分析小分子產(chǎn)生的信號。如圖 1B 所示,研究者選擇了 24 中代謝物檢測:(1) 甲酸,(2)組氨酸,(3)苯丙氨酸,(4)酪氨酸,(5)α- 葡萄糖,(6)脯氨酸,(7)乳酸,(8)肌酐,(9)肌酸,(10)磷酸肌酸,(11)蘇氨酸,(12)膽堿,(13)肌氨酸;(14)檸檬酸鹽,(15)谷氨酰胺,(16)琥珀酸鹽,(17)乙酰乙酸鹽,(18)谷氨酸鹽,(19)乙酸鹽,(20)丙氨酸,(21)β- 羥基丁酸酯,(22)纈氨酸,(23)異亮氨酸和(24)亮氨酸。
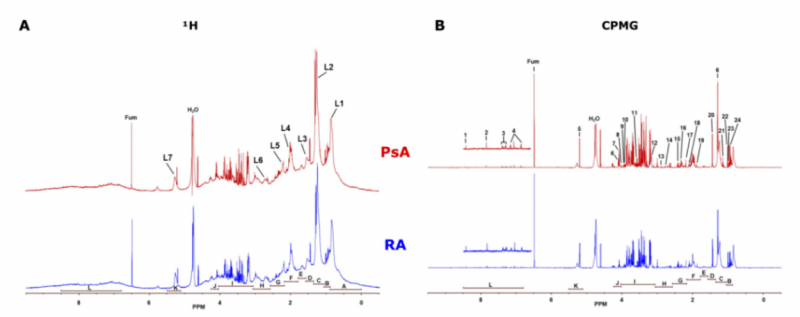 |
圖 1 PsA 和 negRA 患者的光譜特征:1H 單脈沖(A) 和 CPMG NMR(B)
多變量統(tǒng)計分析
對 1H 單脈沖和 CPMG NMR 光譜進行多變量統(tǒng)計分析,以確定是否存在可區(qū)分兩種疾病的特征光譜圖或峰。根據(jù)偏 zuì小二乘判別分析(PLS-DA)和隨機森林模型,臨床或人口統(tǒng)計學(xué)協(xié)變量與 1H(圖 1)和 CPMG(數(shù)據(jù)未顯示)光譜區(qū)域之間沒有顯著相關(guān)性。
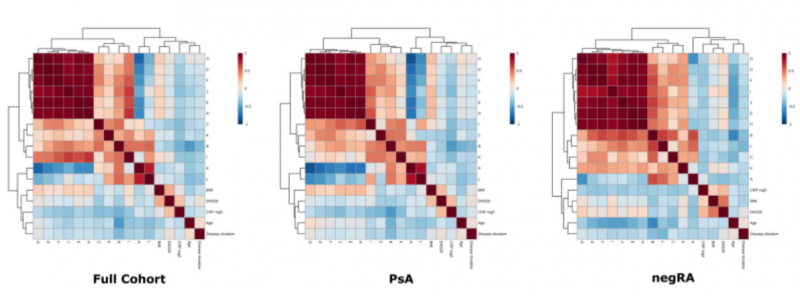 |
圖 2 顯示了臨床 / 人口統(tǒng)計學(xué)變量與 1H 光譜區(qū)域之間的 Pearson 相關(guān)系數(shù),以及用于發(fā)現(xiàn)隊列,PsA 和 negRA 組的歐幾里德度量的分層聚類
由于基于主成分分析的代謝組學(xué)數(shù)據(jù)的聚類通常很困難,用偏 zuì 小二乘法(PLS-DA) 對 1H 和 CPMG 光譜數(shù)據(jù)集進行評價。主成分 1 - 5 表明了 1H 數(shù)據(jù)方差 =96.9%/CPMG 數(shù)據(jù)方差 =84.6%,但聚類并不明顯,無法清晰區(qū)分 PsA 和 negRA 患者(圖 3A)。
圖 3A 五個主成分之間的成對得分曲線圖,對角線上顯示相應(yīng)的方差。
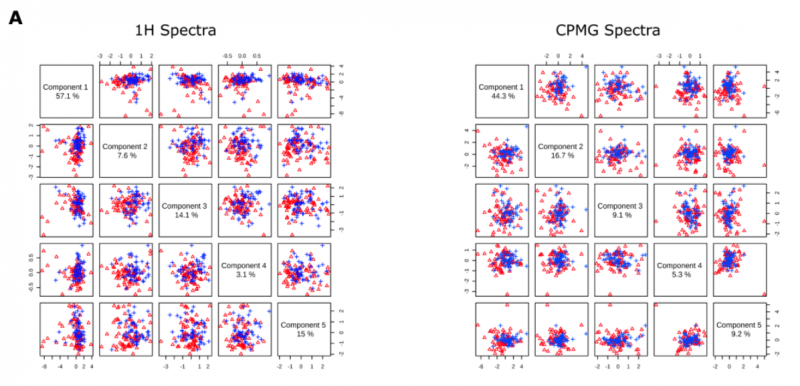 |
在評估 PLS-DA 模型的質(zhì)量時,其準確度≤65%,R2 和 Q2 值都非常低(1H 光譜:R2 = 0.13,Q2 = 0.06;CPMG 光譜:R2 = 0.16,Q2 = 0.08)。為了提高基于光譜模式的診斷準確性,研究者使用了隨機森林分類算法,因為它對高維數(shù)據(jù)分析具有穩(wěn)健性。在 1H 和 CPMG 光譜中,該算法鑒定了對 negRA 和 PsA 患者進行分類的相似區(qū)域,基于 1H 的分類 oob error=0.361,基于 CPMG 的分類 oob error=0.336(圖 3B,C)。盡管如此,通過隨機森林算法確定的重要光譜區(qū)域仍被用于聚焦目標分析。
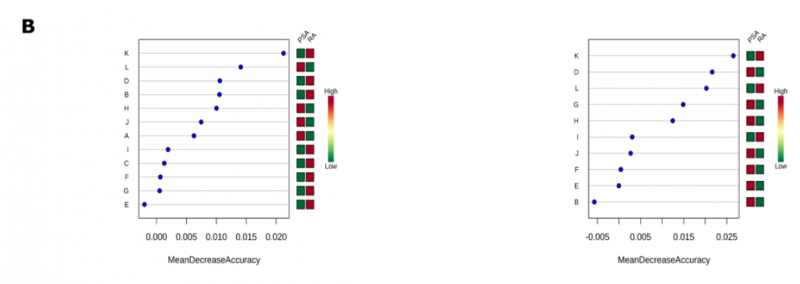 |
圖 3B 隨機森林確定的顯著特征。
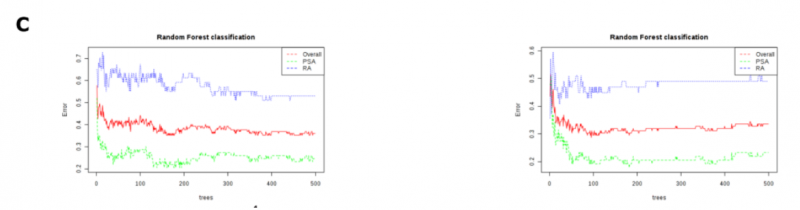 |
圖 3C 隨機森林分類的累積錯誤率。
(紅:總體;藍:RA;綠:PsA)
目標代謝物,脂類聚焦分析
在定量代謝物和脂質(zhì)組的濃度后,通過單變量分析確定患者組之間的差異。在 24 種代謝物中,兩種患者組中的 9 種具有明顯不同的濃度,即氨基酸(AA):丙氨酸,亮氨酸,苯丙氨酸,蘇氨酸和纈氨酸以及有機化合物乙酸鹽,膽堿,肌酸和乳酸。
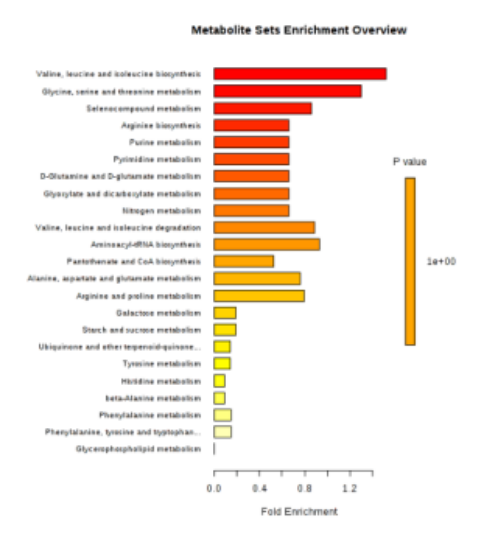
另外發(fā)現(xiàn) negRA 和 PsA 患者之間的脂質(zhì)比率 L3 / L1,L5 / L1 和 L6 / L1 有統(tǒng)計學(xué)差異在 PsA 中均較高(圖 4A)。比較兩組時,某些代謝途徑明顯富集(圖 4B)。
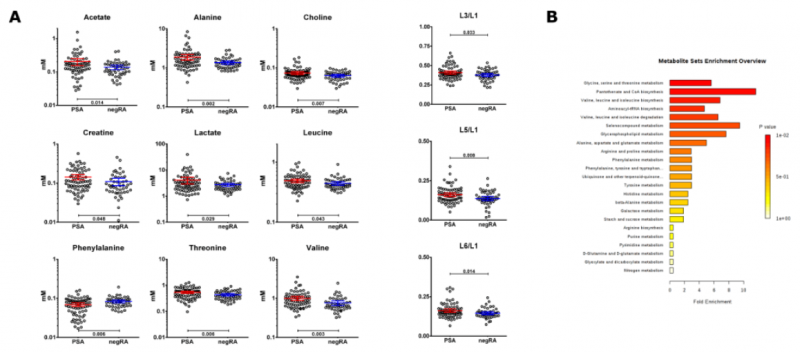 |
圖 4(A)目標分析中包括的代謝物和脂質(zhì)比率的點狀圖,這些點狀圖顯示了發(fā)現(xiàn)隊列中兩個患者組之間的顯著差異。線表示平均值和 95%CI。(B)定量富集分析的摘要條形圖,顯示發(fā)現(xiàn)隊列中 negRA 和 PsA 代謝組之間的變化。
多元方差分析(MANOVA)
年齡,性別和治療方案可能會影響不同疾病中生物體液中代謝物的濃度,從而影響要用于初治患者或不同年齡患者的生物標志物的定義。為了分析任何臨床或人口統(tǒng)計學(xué)參數(shù)是否可能對 24 種代謝物或脂質(zhì)組的血清濃度產(chǎn)生影響,研究者對相關(guān)代謝物和潛在代謝物進行了多元方差分析(MANOVA)。
結(jié)果表明(表格未展示)疾病活動與膽堿濃度,L2 / L1 和 L7 / L1 的變化有關(guān),而疾病持續(xù)時間與檸檬酸鹽,磷酸肌酸,葡萄糖,組氨酸,酪氨酸和纈氨酸濃度的變化有關(guān)。當(dāng)將年齡和體重指數(shù)類別與疾病組結(jié)合時,代謝物濃度和脂質(zhì)比率的變化同樣可見。盡管 RA 是一種主要影響女性的疾病,與 PsA 相反,但 MANOVA 分析結(jié)合了疾病類別和性別,在相關(guān)代謝產(chǎn)物上沒有任何顯著差異。當(dāng)疾病和治療相結(jié)合時,情況類似。單變量分析顯示代謝物濃度或脂質(zhì)比率與臨床和人口統(tǒng)計學(xué)變量之間有沒有任何顯著相關(guān)。如圖 5
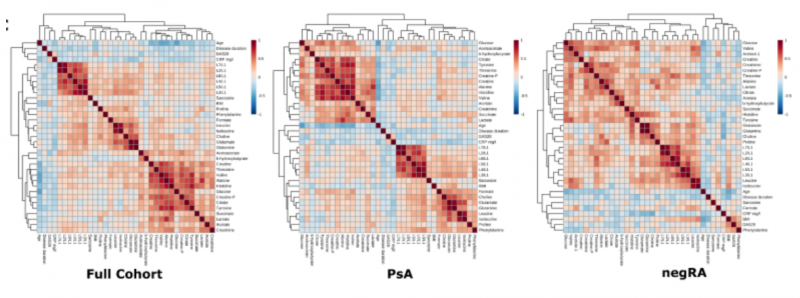 |
圖 5 顯示臨床或人口統(tǒng)計學(xué)變量與代謝物之間的 Pearson 相關(guān)系數(shù),并使用歐幾里德度量對發(fā)現(xiàn)隊列的 PsA 和 negRA 組進行分層聚類。
用于患者分類的多元診斷模型
單一代謝物或脂質(zhì)比例的 ROC 分析得到的曲線下面積(AUC) 小 70%。因此,單變量模型對 PsA 和 negRA 患者的鑒別的敏感性和特異性低。為了達到高的診斷準確率,研究者建立了三種不同的機器學(xué)習(xí)算法:隨機森林算法、樸素貝葉斯算法和多元 Logistic 回歸算法,對 73 例 PsA 和 49 例 negRA 患者的代謝組和脂質(zhì)組進行了分析。隨機森林預(yù)測 PsA 的準確率 73.3%(Cohen‘s kappa 40.1%),樸素貝葉斯準確率為 63.7%(Cohen’s kappa 26.5%)。
通過逐步向前 - 向后選擇算法,以下診斷預(yù)測因子已包括在診斷模型中:年齡,性別,L6 / L1,L5 / L1,L2 / L1,丙氨酸,琥珀酸和磷酸肌酸。
在驗證過程中,使用十折交叉驗證對所得到的模型進行評估,這產(chǎn)生了表 1 中的系數(shù)估計。
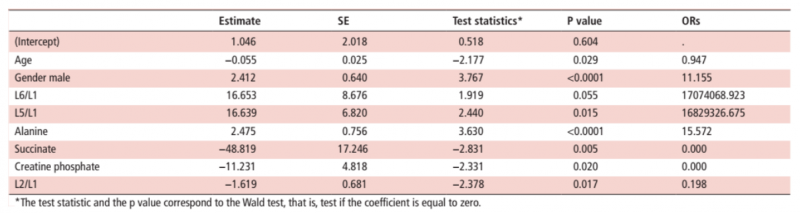 |
表 1 模型系數(shù)的評估
將這些估計值應(yīng)用到回歸模型中會產(chǎn)生以下公式:
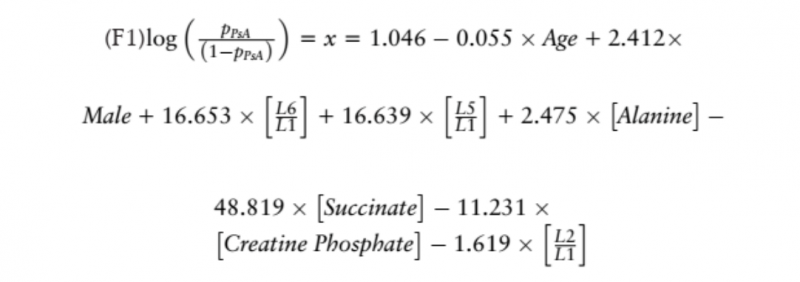 |
每種代謝物的濃度、年齡和性別(男性 =1,女性 =0) 代入公式中。然后,通過替換在 F1 中獲得的結(jié)果×來計算屬于 PsA 組的概率:
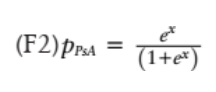
患者屬于 negRA 組的概率由下式給出:
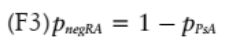
將患者分為兩組,需計算概率(F2) 的分界值。通常應(yīng)用分界值 0.5,PPsA>0.5,則將其分類為 PsA,這反映了將對象分類為更有可能進行診斷的想法。圖 6 為發(fā)現(xiàn)隊列中交叉驗證的建模概率 PPsA 的 ROC 曲線,該圖顯示了該模型對此臨界值的敏感性和特異性,ROC 曲線下的總面積(AUC) 為 84.5%。
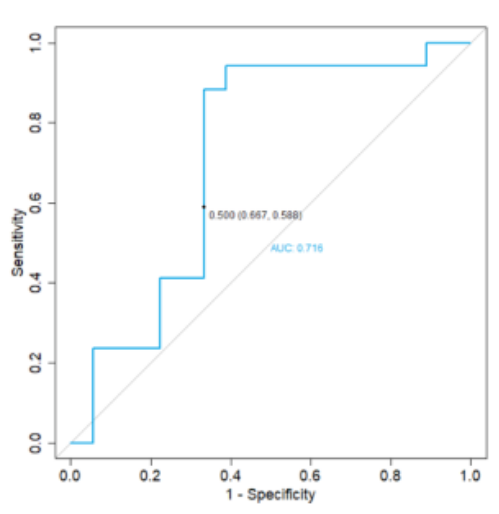
為了進一步驗證從交叉驗證過程中檢索到的模型,研究者收集了 35 名新的關(guān)節(jié)炎患者的單獨的盲法樣本。該隊列與用于建立診斷模型的隊列具有相似的路徑分布(圖 7)。使用臨界值 0.5 對盲法隊列進行評估,得出了 62.9% 的患者的正確預(yù)測,并進行了 ROC 分析,其中 AUC 降至 71.6%(圖 8)。
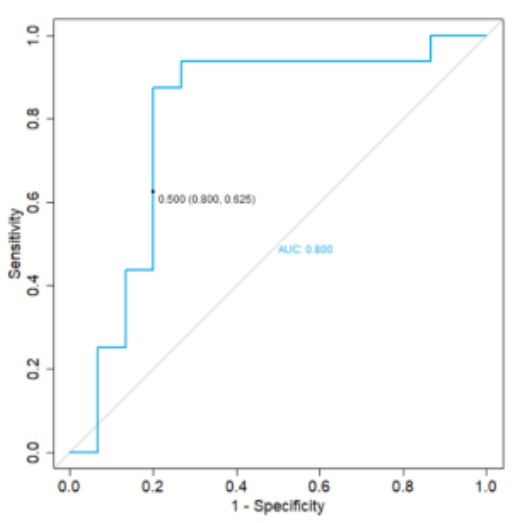
在診斷預(yù)測后,對 13 名預(yù)測診斷與風(fēng)濕科醫(yī)生 zuì 初所做的診斷不同的患者進行了臨床重新評估。對于這些患者中的 4 名,仍然無法確定診斷,因為他們一直缺乏獨特的臨床參數(shù)。研究者從驗證隊列中刪除了這四個個體,重新計算了預(yù)測匹配率,增加到 71.0%,并進行了新的 ROC 分析,結(jié)果提高了敏感度(62.5%) 和特異度(80.0%)(圖 9)。
|
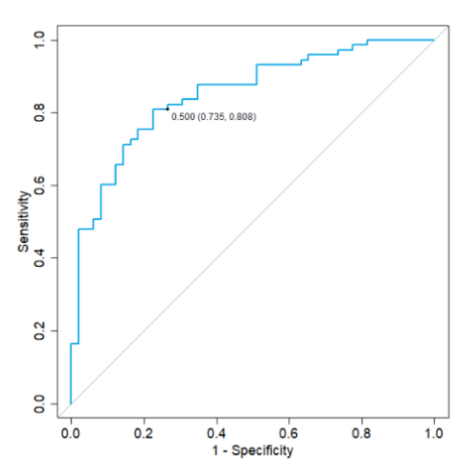
▲圖 6
 |
 |
▲ 圖 8
 |
結(jié)論
為驗證其在基因異源人群中的有效性,還需要在更大的多國 / 多民族隊列中進行測試。盡管如此,研究者的研究有助于將 1HNMR 的代謝組學(xué)這一技術(shù)擴展到自身免疫病理學(xué)的常規(guī)診斷技術(shù)鋪平道路。即使臨床特征相似,與風(fēng)濕性疾病相關(guān)的代謝組學(xué)過程在疾病之間也有所不同。因此,代謝組學(xué)和脂質(zhì)組學(xué)開始為自身免疫研究提供一個全新的領(lǐng)域。
參考文獻
Margarida souto-carneiro,lilla Tóth,rouven Behnisch,et al. Differences in the serum metabolome and lipidome identify potential biomarkers for seronegative rheumatoid arthritis versus psoriatic arthritis. Ann Rheum Dis.2020; 79(4):499-506.
更多伯豪生物服務(wù)

